◆ 우선 개발환경은 Python 3.11 버전에, Visual Studio Code를 사용하였다.
◆ 기본 데이터에서 데이터 정제
bigkinds에서 가져온 데이터라면, "키워드" 필드에 있는 데이터를 그대로 사용해도 무방할 듯 하다.
import pandas as pd
dataFile = './NewsResult.xlsx'
df = ''
if dataFile.endswith('.xlsx'):
df = pd.read_excel(dataFile)
elif dataFile.endswith('.csv'):
df = pd.read_csv(dataFile)
df = df[["키워드"]]
print("> original data")
print(df.head(5))
# 혹시 데이터 정제가 필요하면, 정제 함수를 만들고 아래처럼 호출
df["키워드"] = df["키워드"].map(refine_data)
def refine_data(text):
try:
text = re.sub('\\\\n', ' ', text)
text = re.sub('[^가-힣ㄱ-ㅎㅏ-ㅣa-zA-Z]', ' ', text)
text = re.sub('[\s]+', ' ', text)
return text
except Exception as e:
print("error = ", e)
return ''
데이터를 읽어와서 토큰화하자
token_list = []
empty_count = 0
for k in df["키워드"]:
nouns = k.split(',') # 이미 키워드로 뽑은것이라, konlpy 를 쓸 필요가 없음.
static_nouns = find_static_nouns(k) # 기타 static 명사 추가. ex) konly로 찾지 못하는 예외 케이스들을 따로 찾아서 리스트로 리턴
nouns = [*nouns, *static_nouns]
line = []
for n in nouns:
if len(n) > 0:
line.append(n)
if (len(line) == 0): # 간헐적으로 정제후 전혀 키워드가 안뽑힌 경우도 있을 수 있음
empty_count += 1
line = ''
else:
line = "|".join(line)
token_list.append(line)
df["키워드"] = pd.DataFrame(token_list, columns = ["키워드"])
그외 추가 필터링, 처리 작업
# 단어 변경이 필요할 때
print("> replace_array_words")
df["키워드"] = df["키워드"].map(replace_array_words)
# 불필요한 키워드 제거
print("> remove_stopwords")
df["키워드"] = df["키워드"].map(remove_stopwords)
# 빈 라인이 있으면 제거
df = df[ (df["키워드"].notnull()) & (df["키워드"].str.len() > 0) ]
print(df[outputFieldToken].head(5))
#파일 출력
df.to_excel('./df.xlsx', index=False)
print("> df.xlsx exported")
konlpy로 명사를 추출하면, 1글자는 추출하지 않는 문제?가 있다.
1글자 키워드를 추출한다고 하면 너무 많은 키워드가 만들어질거 같긴하다. 1글자 키워드를 포함시키기 위해서 별도의 예외처리 코드가 필요할 것이다. 그리고 제한적으로 정해진(즉, 유의미한) 1글자 키워드만 포함시켜야 할 듯하고, 1글자 특성상 다른 단어의 일부에 포함되었을 경우가 들어 가지 않게 처리가 필요할 듯 하다.
예를 들어 "나" (Me) 라는 키워드가 유의미 하다면, 단순히 텍스트에서 "나"가 포함 되었는지만을 찾는다면 문제가 될 소지가 크다. "언제나" "만나서" 이런 단어에도 포함이 되었다고 카운트 될 것이기 때문이다.
공백까지 같이 찾거나, "나에게" "나를" 등의 키워드로 찾아서 replace 하는 등의 예외처리가 필요하다. 데이터를 보고 판단할 필요가 있어 조금은 번거로운 일이 될듯하다. (여전히 인간의 노가다?는 아직 필요한듯하다. GPT같은 LLM이 나와서 대체가 가능할 듯도 하지만 그것은 또한 비용 증가로 이어질 것이다)
그리고, 특정 키워드 제거나, 텍스트 replace를 할 때도, 단순히 전체 텍스트에 대해서 in 등으로 찾지말고,
divider 로 split 한 다음에 키워드가 완전히 동일한 지를 체크해서 처리해야 의도치 않은 수행을 막을 수 있을듯 하다.
* 기타 필터링/대체 함수는 아래처럼 구현했다.
# 1. 특별히 허용할 단어나 글자
def find_static_nouns(text):
result = []
KEYWORDS = [
"새로움", '나를', '나에게', '나 자신', '나에대해', '길을 ' #공백은 의도한 것
]
result = [key for key in KEYWORDS if key in text]
return result
# 2. 특별히 단어를 변환해야 할 경우. 1번에서 특별히 허용한 단어를 특정 키워드로 변환 필요
def replace_array_words(text):
REPLACE_WORDS = [
("물이", "물"),
("마주", "마주하기"),
("나에게", "나"),
("나를", "나"),
("나 자신", "나"),
("나에대해", "나"),
("길을 ", "길"),
]
arr_text = text.split('|')
for a, b in REPLACE_WORDS:
arr_text = [b if t == a else t for t in arr_text]
return "|".join(arr_text)
# 3. 불용어 제거 및 한글자 허용 (토큰 단위 처리)
def remove_stopwords(text):
try:
tokens = text.split('|')
stops = ['투데이','최근','성형', '대한', '현지','지난','기자']
meaningful_words = [w for w in tokens if not w in stops]
allow_one_lnth = ['물', '나', '삶', '책', '길']
result = []
for w in meaningful_words:
if len(w) != 1 or w in allow_one_lnth:
result.append(w)
return '|'.join(result)
except Exception as e:
print("error = ", e)
return ''
파이썬 문법 자체가 아직 익숙치 않은 초보라, 코드를 잘 최적한 한것인지 자신은 없다.
입력 데이터를 정교하게 분석이 필요할 수록 이런 필터링 함수가 복잡해질듯 하다. (특히 1글자 토큰 지원을 위해서는...)
→ 위 예시 케이스는 입력 데이터가 대략 800여개여서 눈으로 어느 정도 확인이 가능했다. 수천 수만개의 입력데이터라면 1토큰은 거의 포기를 해야지 않을까 싶다.
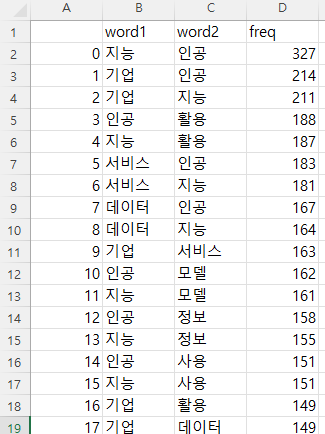
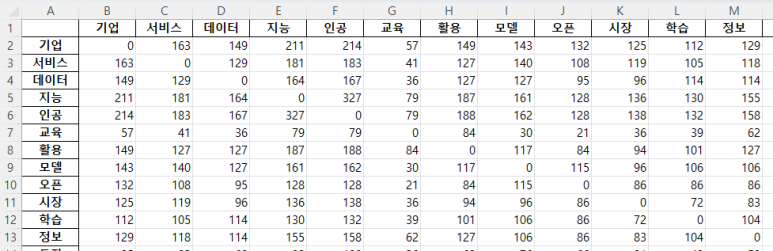
결과파일(df.xlsx)는 대략 이런식으로 저장될 것이다.