import console from 'console';
import config from 'config';
export function createContext($vivContext) {
// console.log(JSON.stringify($vivContext));
let {locale} = $vivContext;
let instruction = getInstruction();
let gptDialog;
locale = locale.toLowerCase();
let kidName = getKidName(locale);
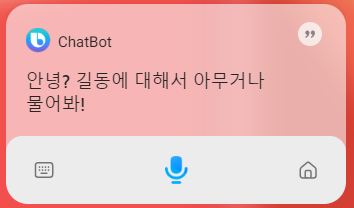
if (locale == 'ko-kr') {
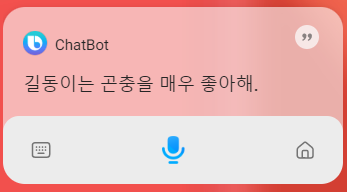
gptDialog = `안녕? ${kidName}에 대해서 아무거나 물어봐!`;
} else if (locale == 'en-us') {
gptDialog = `Hello? Do you have any questions about ${kidName}?`;
} else {
gptDialog = `Hello? Do you have any questions about ${kidName}?!`;
console.error('Should not be here');
}
let conversation = [
{ 'role': 'assistant', 'content': gptDialog }
];
// instruction과 대화이력은 따로 저장한다. instruction이 잘려나가지 않도록 별도로.
return {
instruction,
conversation : JSON.stringify(conversation),
gptDialog,
locale
}
}
function getInstruction() {
let instruction = '너는 친절한 인공지능 챗봇이고, 유저와 재미있는 퀴즈를 서로 주고 받을 수 있어. 응답은 50자 정도로 짧게 해줘';
let instArr = [];
let insCount = 0;
try {
insCount = config.get('instruction.count'); // instruction line 개수
for (let i = 0; i < insCount; i +=1 ) {
let key = 'instruction.key' + String(i);
instArr.push(config.get(key));
}
if (instArr.length > 0) {
instruction = instArr.join('\r\n');
}
console.log('getInstruction > ' + instruction);
} catch (e) {
console.log(e.toString());
}
return instruction;
}
function getKidName(locale) {
try {
let name = config.get('kid.name.' + locale.replace('-', '')); // config key는 하이픈을 허용하지 않는다.
// console.log('kid.name = ' + name);
return name;
} catch (e) {
console.log(e.toString());
}
return '';
}
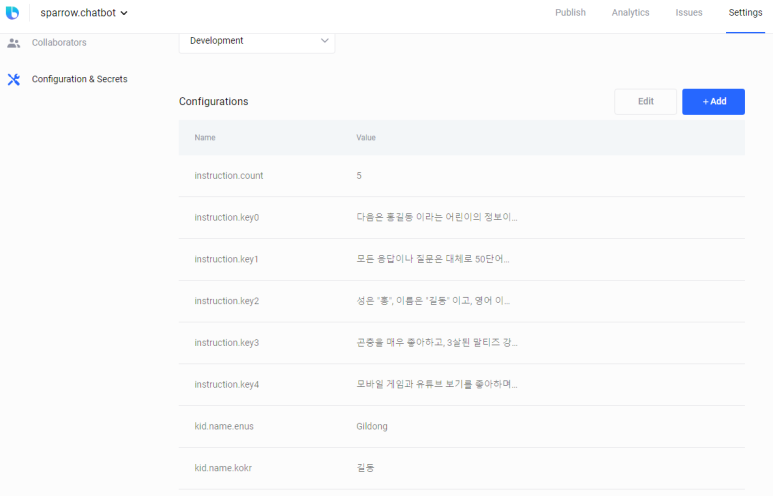
→ GPT API 호출시 instruction을 읽어오는 부분이다. instruction은 빅스비 데브 센터의 config에 저장을 해두었다.
캡슐 코드를 바꿀 필요없이, config에서 변경을 하면 거의 실시간으로 반영된다.
아이의 이름도 config에 저장을 해두었다.
Instruction은 5개로 나누어서 저장을 해서, 코드상에서 합치도록 했다. config의 value는 500자 정도까지 가능한것으로 알고 있어서, 나누어서 저장을 했다.
* config 메뉴 하단에 secret도 있는데, 여기에 Open AI API key를 저장해두었다. 그래서 코드상에서는 key가 없다.
* config 화면에 mode가 있는데, Development와 Public 두가지가 있다. 두가지 mode 모두에 값들을 저장해주어야 한다. Development는 IDE나 private revision으로 테스트할 때 사용되고, public은 배포용 버전 (public revision)에서 사용된다.
import console from 'console';
import http from 'http';
import secret from 'secret';
export function callApi(context, query) {
let newMessages = [
{'role': 'system', 'content': context.instruction}
];
let conversation = JSON.parse(context.conversation);
conversation.push(
{'role': 'user', 'content': query},
);
newMessages = newMessages.concat(conversation);
let body = {
messages: newMessages,
model: 'gpt-3.5-turbo'
}
let nextGptDialog = call(body);
conversation.push(
{'role': 'assistant', 'content': nextGptDialog},
);
// Context 길이 제약이 있기때문에 적당히 잘라내자.
if (conversation.length > 10) {
conversation = conversation.slice(conversation.length - 10);
}
return {
instruction : context.instruction,
conversation : JSON.stringify(conversation),
gptDialog : nextGptDialog,
locale : context.locale
};
}
function call(body) {
let url = 'https://api.openai.com/v1/chat/completions';
let options = {
format: 'json',
headers: {
'Content-Type': 'application/json',
'Authorization' : 'Bearer ' + secret.get('gpt.key'),
},
};
let response = http.postUrl(url, body, options);
console.log(JSON.stringify(response));
return response.choices[0].message.content;
}
→ OpenAI API를 호출하는 부분이다. Instruction과 이전 대화기록, 현재 유저가 응답한 메시지를 다 합쳐서 API로 호출한다. 응답을 받으면 그걸 다시 빅스비가 읽어주게 되어 있다.
알다시피, 이전 대화기록을 Open AI 서버에서 저장을 해주지 않는다. 우리쪽에서 이전 대화기록을 보관했다가 API 호출시 같이 전달해야 한다. 이전 기록이 길어지면 토큰 limit에 도달할 수 있으므로, 적당히 최근 10개 대화만 보내도록 처리를 했다.
한번의 대화를 하고 나서, 계속 대화가 되도록 (마이크가 자동으로 on), 계속 반복 동작하도록 모델링을 구현하였다.
// StartChat.js
import console from 'console';
import fail from 'fail';
import * as gpt from "./lib/gptApi.js";
export default function (input) {
const { context, query } = input
console.log('StartChat : ', query);
let nextContext = gpt.callApi(context, query);
// 대화를 계속 이어가게 하기 위해서, 자신을 다시 호출하게 함. StartChat.model.bxb 의 output 부분 참조.
throw fail.checkedError(
'Go Next chat',
'NextChat',
{
nextContext,
}
);
}
// StartChat.model.bxb
// ...
output (Context) {
throws {
error (NextChat) {
property (nextContext) {
type (Context)
min (Required) max (One)
visibility (Private)
}
on-catch {
// 아래처럼 replan을 통해서 다시 동작하게 한다.
// 이전 기록은 nextContext라는 구조체에 저장되어 전달된다.
replan {
intent {
goal : StartChat
value : $expr(nextContext)
}
}
}
}
}
}
서비스형 플랫폼 PaaS (Platform as a Service) 중에 대표적인 서비스로 Heroku가 있다.
예전엔 free tier로 사용하는 것도 가능했는데, 지금은 최소 월 5달러 짜리 (시간당 부과 가능) 사용을 해야 되긴 하다.
서비스형 플랫폼(PaaS) 모델에서 개발자는 기본적으로 개발 도구, 인프라, 운영 체제를 클라우드 공급자에 의존하여 애플리케이션을 구축하는 데 필요한 모든 것을 대여합니다. 이는 클라우드 컴퓨팅의 세 가지 서비스 모델 중 하나입니다. PaaS 덕분에 웹 애플리케이션 개발이 대폭 간소화되며, 개발자 입장에서는 모든 백엔드 관리가 백그라운드에서 이루어집니다. PaaS는 서버리스 컴퓨팅과 몇 가지 유사점이 있지만, 이 둘 사이에는 중요한 차이점이 많습니다. 서비스형 플랫폼(PaaS)이란? | Cloudflare
"New platform updates from DevDay: GPT-4 Turbo, Assistants API, new modalities + GPTs in ChatGPT"
오늘 DevDay가 있었고, ChatGPT 업데이트가 있었다.
▶ GPT4
API로 GPT4가 사용이 가능해졌고, 128K Context size 채팅(API아님)이 가능해졌다는 점
이제 API쓸때 GPT4 모델을 쓰면 32K context size까지 쓸 수 있다.
최신 데이터. 23년 4월까지 데이터가 들어 갔다고 한다.
▶GPT3
가격 인하? 디폴트로 16K 사이즈로 변경될 예정. (12월 11일부터 1106 모델이 디폴트로 적용되는 듯)
가격은 인풋에 대해서 기존 0.0015달러에서 0.0010 달러로 내렸다. (기존은 4K 이고, 이제 디폴트가 16K라 더 내린거라 봐도 될려나 싶다. 기존 16K 모델은 0.003달러였으므로 1/3로 내린거긴 하다)
16K 모델 파인튜닝 가능
32K 사이즈 모델을 쓰려면 가격이 60배 비싸다. 지금 상담용 챗봇은 4K 사이즈로 개발을 하고 있는데, 1번의 상담을 하고 나면 대~략 20원 정도였다, 32K 모델로 쓴다고 가정하면, 단순 계산으로 1200원이 된다. 사이즈가 늘었으니 대화도 더 길게 끌고 간다고 하면 비용이 엄청 커지겠다.
첫 번째 컨퍼런스인 OpenAI DevDay에서 발표된 주요 새로운 기능과 업데이트를 공유하게 되어 기쁩니다. 블로그에서 자세한 내용을 읽거나, 기조 연설 녹화본을 보거나, 새로운 @OpenAIDevs Twitter를 확인할 수 있지만 여기에 간략한 요약이 있습니다.
새로운 GPT-4 터보:
가장 진보된 모델인 GPT-4 Turbo를 발표했습니다. 128K 컨텍스트 창과 2023년 <>월까지의 세계 이벤트에 대한 지식을 제공합니다.
GPT-4 Turbo의 가격을 상당히 인하했습니다: 입력 토큰은 이제 $0.01/1K , 출력 토큰은 $0.03/1K로 이전 GPT-3 가격에 비해 각각 2배 및 4배 저렴합니다.
단일 메시지에서 여러 함수를 호출하고, JSON 모드를 사용하여 항상 유효한 함수를 반환하고, 올바른 함수 매개 변수를 반환하는 정확도를 개선하는 기능을 포함하여 함수 호출을 개선 했습니다.
모델 출력은 새로운 재현 가능한 출력 베타 기능을 통해 보다 결정적입니다.
API에서 gpt-4-4-preview를 전달하여 GPT-1106 Turbo에 액세스할 수 있으며 , 올해 말에 안정적인 프로덕션 준비 모델 릴리스가 계획되어 있습니다.
업데이트된 GPT-3.5 터보:
새로운 gpt-3.5-turbo-1106은 기본적으로 16K 컨텍스트를 지원하며 4배 더 긴 컨텍스트를 더 저렴한 가격($0.001/1K 입력, $0.002/1K 출력)으로 사용할 수 있습니다. 이 16K 모델의 미세 조정이 가능합니다.
미세 조정된 GPT-3.5는 입력 토큰 가격이 $75.0/003K로 1% 감소하고 출력 토큰 가격이 $62.0/006K로 1% 감소하여 훨씬 저렴합니다.
gpt-3.5-turbo-1106은 향상된 함수 호출 및 재현 가능한 출력으로 GPT-4 Turbo에 합류합니다.
어시스턴트 API:
애플리케이션에서 에이전트와 유사한 환경을 손쉽게 구축할 수 있도록 설계된 새로운 어시스턴트 API의 베타 버전을 소개하게 되어 기쁩니다. 사용 사례는 자연어 기반 데이터 분석 앱, 코딩 도우미, AI 기반 휴가 플래너, 음성 제어 DJ, 스마트 시각적 캔버스 등 다양합니다
이 API를 사용하면 특정 지침을 따르고, 추가 지식을 활용하고, 모델 및 도구와 상호 작용하여 다양한 작업을 수행할 수 있는 특수 목적의 AI 도우미를 만들 수 있습니다.
어시스턴트에는 개발자가 스레드 상태 관리를 OpenAI에 전달하고 컨텍스트 창 제약 조건을 해결할 수 있는 영구 스레드가 있습니다. 또한 코드 인터프리터, 검색 및 함수 호출과 같은 새로운 도구를 사용할 수 있습니다.
당사 플랫폼인 Playground를 사용하면 코드를 작성하지 않고도 이 새로운 API를 사용할 수 있습니다.
멀티모달 기능:
GPT-4 Turbo는 이제 Chat Completions API에서 시각적 입력을 지원하여 캡션 생성 및 시각적 분석과 같은 사용 사례를 가능하게 합니다. gpt-4-vision-preview 모델을 사용하여 비전 기능에 액세스할 수 있습니다. 이 비전 기능은 올해 말 프리뷰가 출시될 GPT-4 Turbo의 프로덕션 준비 버전에 통합될 예정입니다.
DALL· E 3 - 이미지 생성 API를 통해 애플리케이션으로 이미지를 생성합니다.
새로 도입된 TTS 모델을 통해 텍스트 음성 변환 기능을 출시했으며, 이 모델은 6가지 자연스러운 음성 중 하나를 사용하여 텍스트를 읽어줍니다.
ChatGPT의 사용자 지정 가능한 GPT:
GPT라는 새로운 기능을 출시했습니다. GPT는 지침, 데이터 및 기능을 맞춤형 버전의 ChatGPT로 결합합니다.
DALL· E 또는 Advanced Data Analysis, GPT는 개발자 정의 작업도 호출할 수 있습니다. GPT를 사용하면 개발자가 경험의 더 많은 부분을 제어할 수 있습니다. 우리는 의도적으로 플러그인과 액션을 매우 유사하게 설계했으며 기존 플러그인을 액션으로 전환하는 데 몇 분 밖에 걸리지 않습니다. 자세한 내용은 문서를 참조하세요.
GPT API 호출시 모든 비용은 토큰 수에 따라 계산이 되므로, 대략 어느정도의 토큰이 사용이 되는지를 알아야 비용 계산을 할 수 있다.
Python 같은 경우 tiktoken이라는 모듈로 이미 Open AI에서 제공하는 것이 있어서 참고를 할 수 있다.
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613"):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0613": # note: future models may deviate from this
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\n
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistant
return num_tokens
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not presently implemented for model {model}.
See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
Node js 에서 코드상에서 토큰을 세는 방법은 tiktoken이라는 모듈을 설치후에 가능하다.
(아마 open ai에서 공식적으로 제공한 패키지는 아닌것으로 알고있다.)
import { get_encoding, encoding_for_model } from "tiktoken";
function tiktoken_test() {
let encoding = encoding_for_model("gpt-3.5-turbo");
// encoding = get_encoding("cl100k_base"); // 일반적으로 gpt3.5 와 4에서 사용하는 인코더를 가져옴. 추천방식
let encoded = encoding.encode("안녕하세요. 제 이름은 이호영입니다.");
console.log(encoded);
console.log('length = ', encoded.length);
encoded = encoding.encode("Hello. My name is Hoyeong Lee");
console.log(encoded);
console.log('length = ', encoded.length);
}
tiktoken_test();
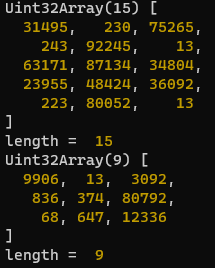
위 테스트 코드를 실행해보면,
와 같이, 토큰별 ID와 길이를 알 수 있다. 토큰은 Uint32Array라는 배열로 저장된다.
토큰이 어떻게 나눠지는지 알아보기 위해 토큰별로 글자를 프린트 해보겠다.
const encoding = get_encoding("cl100k_base");
const textDecode = new TextDecoder();
function testCountToken() {
let encoded = encoding.encode("안녕하세요. 제 이름은 이호영입니다. 성은 이, 이름은 호영입니다.");
console.log(encoded);
let decoded = textDecode.decode(encoding.decode(encoded));
console.log(decoded);
}
실행해보면,
토큰 ID가 나오고 있고, 전체 문장을 디코딩하면 원래 문장으로 잘 나오고 있다.
const encoding = get_encoding("cl100k_base");
const textDecode = new TextDecoder();
function testCountToken() {
let encoded = encoding.encode("안녕하세요. 제 이름은 이호영입니다. 성은 이, 이름은 호영입니다.");
displayDecodedCharacters(encoded);
console.log('token length = ', encoded.length);
}
function displayDecodedCharacters(encoded) {
let idx = 0;
for (let key in Object.keys(encoded)) {
let arr = new Uint32Array(1);
arr[0] = encoded[key];
let ch = textDecode.decode(encoding.decode(arr), {stream:true});
console.log(`${idx} : ${encoded[key]}="${ch}"`);
idx += 1;
}
}
encode 된 Uint32를 한개씩 가져와서 길이 1인 배열에 첫번째 인덱스에 값을 넣고, 디코딩을 했다.
실행을 해보면 아래처럼 나온다.
첫번째 인자는 토큰 내부 로직을 자세히몰라서 왜 빈칸인지는 잘 모르겠다. 중간중간에도 빈칸이 존재한다. 컴마등의 기호에도 토큰이 붙는다.
"호"라는 글자가 공백 뒤에 있을때와 다른글자 뒤에 있을때 각각 다른 ID로 지정되고 있다. 공백+글자 이렇게 묶어서 토큰이 되는것으로 알고 있다.
이번엔 영어로 해보았다.
let encoded = encoding.encode("Hello. My name is Hoyeong Lee, First name is Hoyeong and last name is Lee.");
한글과는 달리, 첫번째 인자는 빈칸이 아니긴했다. 한글이 토큰 비용면에서 불리한 느낌이 있다.
토큰수를 대략 알고 있으면, 아래 pricing 페이지에서 비용을 참고하여 계산할 수 있겠다.
비용은 1000토큰 단위로 부과가 되는듯하고, Input(API 요청) Output (API 응답)에 따라 비용이 다르고, 보통 아웃풋이 더 비싸게 책정되어 있다.
현재 gpt3.5 모델 대비 4.0 모델은 30배 정도 비싸게 부과된다.
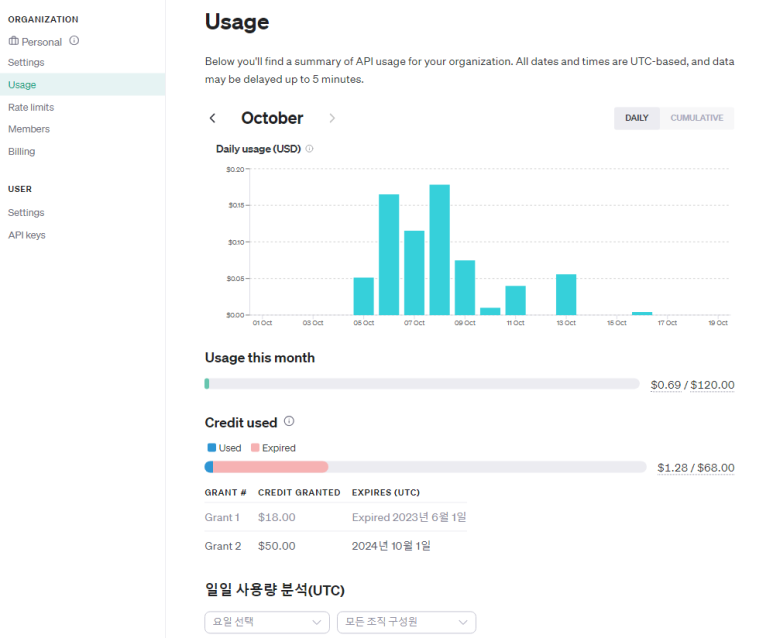
아주 대략적으로 10번의 일반적인 짧은 대화를 주고받고 나면 5k 토큰정도 소요되었고(상담용 챗봇 테스트 기준)