키워드 간의 관계를 파악하기 위해서, 모든 키워드(토큰)들에 대해서, 다른 키워드들과 동시 출현 빈도를 계산할 필요가 있다.
Centrality (연결 중심성, 위세 중심성) 값들을 계산하거나, Network 분석을 위해서 계산을 해 둘 필요가 있다.
동시 출현값은, 키워드를 두개의 쌍으로 해서 동시 출현 횟수를 모두 세어야 하므로, TF값이 높은 키워드들 중에서 Top N개에 대해서만 계산하는 게 유리하다. N이 늘어날 수록 계산량이 제곱만큼 거지므로 시간이 매우 늘어나게 된다.
로컬 PC에서 돌렸는데, 대략 100개~200개 까지 했었다. 사실 그 보다 큰 갯수를 해서 네트워크 그래프를 그린다면 눈에 잘 안들어오는 것도 사실이라 클 필요는 없어 보인다.
import pandas as pd
maxWordForConcurrency = 100 #상위 100개에 대해서만 하려고 한다.
def main():
word_count = pd.read_excel('./count_tf.xlsx', header=None)
word_count = word_count.head(maxWordForConcurrency)
word_list=list(word_count[0].values.astype('U'))
con_count=[[0]*n for i in range(n)]
df = pd.read_excel('./df.xlsx')
contents_list=list(df["내용 토큰화"].values.astype('U'))
# 두 키워드가 같은 문서에 나온 경우를 count
for y in range(maxWordForConcurrency):
for x in range(maxWordForConcurrency):
cc = 0
if y == x: #자기 자신이 동시에 나온 문서를 카운트할 필요는 없으므로 skip
continue
for content in contents_list:
if word_list[x] in content and word_list[y] in content:
con_count[y][x] += 1
# 2개의 키워드가 동시 출현한 문서 수를, 리스트형태로 데이터화 한 뒤에 정렬
count_list = []
for y in range(maxWordForConcurrency):
for x in range(maxWordForConcurrency):
if y > x:
continue
count_list.append([word_list[y], word_list[x], con_count[y][x]])
df = pd.DataFrame(count_list, columns=["word1", "word2", "freq"])
df = df.sort_values(by=['freq'], ascending=False)
df = df.reset_index(drop=True)
# 동시 출현 키워드 쌍을 정렬하여 표시. 중심성 계산할 때 필요
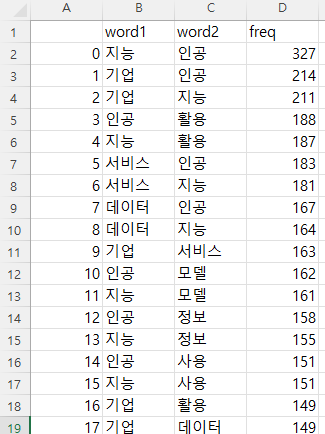
df.to_csv('./concurrency_list.csv', encoding='utf-8-sig')
print("> exported concurrency_list")
# x * x 배열의 sheet 형태로 빈도수 저장. 네트워크 분석 시 필요
cc2 = pd.DataFrame(con_count, columns=word_list, index=word_list)
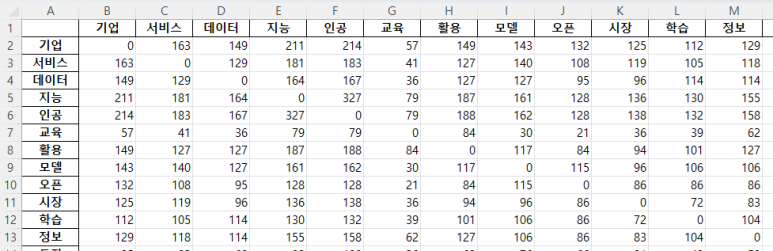
cc2.to_excel('./concurrency_sheet.xlsx', index=True, header=True)
print("> exported concurrency_sheet")
결과 아래와 같은 형태의 두개의 엑셀 파일이 생성되겠다.
'SW Project > 빅데이터 키워드 네트워크 분석' 카테고리의 다른 글
| 빅데이터 키워드 분석 : Word Cloud 그리기 (0) | 2023.11.19 |
|---|---|
| 빅데이터 키워드 분석 : 연결 중심성, 위세 중심성 계산 (Centrality) (0) | 2023.11.19 |
| 빅데이터 키워드 분석 : Term Frequency, TF-IDF 계산 및 막대그래프(plot-bar) 그리기 (0) | 2023.11.19 |
| 빅데이터 키워드 분석 : 개발환경, 데이터 정제 (0) | 2023.11.19 |
| 빅데이터 키워드 분석 : 데이터 수집 (0) | 2023.11.19 |