Open AI API 사용시 토큰 계산(node js) 및 비용
GPT API 호출시 모든 비용은 토큰 수에 따라 계산이 되므로, 대략 어느정도의 토큰이 사용이 되는지를 알아야 비용 계산을 할 수 있다.
Python 같은 경우 tiktoken이라는 모듈로 이미 Open AI에서 제공하는 것이 있어서 참고를 할 수 있다.
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613"):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0613": # note: future models may deviate from this
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\n
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistant
return num_tokens
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not presently implemented for model {model}.
See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
또는, 아래 사이트에서 텍스트를 넣어서 알수도 있다.

Node js 에서 코드상에서 토큰을 세는 방법은 tiktoken이라는 모듈을 설치후에 가능하다.
(아마 open ai에서 공식적으로 제공한 패키지는 아닌것으로 알고있다.)

import { get_encoding, encoding_for_model } from "tiktoken";
function tiktoken_test() {
let encoding = encoding_for_model("gpt-3.5-turbo");
// encoding = get_encoding("cl100k_base"); // 일반적으로 gpt3.5 와 4에서 사용하는 인코더를 가져옴. 추천방식
let encoded = encoding.encode("안녕하세요. 제 이름은 이호영입니다.");
console.log(encoded);
console.log('length = ', encoded.length);
encoded = encoding.encode("Hello. My name is Hoyeong Lee");
console.log(encoded);
console.log('length = ', encoded.length);
}
tiktoken_test();
위 테스트 코드를 실행해보면,
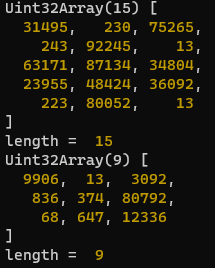
와 같이, 토큰별 ID와 길이를 알 수 있다. 토큰은 Uint32Array라는 배열로 저장된다.
토큰이 어떻게 나눠지는지 알아보기 위해 토큰별로 글자를 프린트 해보겠다.
const encoding = get_encoding("cl100k_base");
const textDecode = new TextDecoder();
function testCountToken() {
let encoded = encoding.encode("안녕하세요. 제 이름은 이호영입니다. 성은 이, 이름은 호영입니다.");
console.log(encoded);
let decoded = textDecode.decode(encoding.decode(encoded));
console.log(decoded);
}
실행해보면,
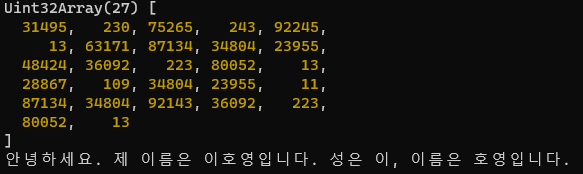
토큰 ID가 나오고 있고, 전체 문장을 디코딩하면 원래 문장으로 잘 나오고 있다.
const encoding = get_encoding("cl100k_base");
const textDecode = new TextDecoder();
function testCountToken() {
let encoded = encoding.encode("안녕하세요. 제 이름은 이호영입니다. 성은 이, 이름은 호영입니다.");
displayDecodedCharacters(encoded);
console.log('token length = ', encoded.length);
}
function displayDecodedCharacters(encoded) {
let idx = 0;
for (let key in Object.keys(encoded)) {
let arr = new Uint32Array(1);
arr[0] = encoded[key];
let ch = textDecode.decode(encoding.decode(arr), {stream:true});
console.log(`${idx} : ${encoded[key]}="${ch}"`);
idx += 1;
}
}
encode 된 Uint32를 한개씩 가져와서 길이 1인 배열에 첫번째 인덱스에 값을 넣고, 디코딩을 했다.
실행을 해보면 아래처럼 나온다.

첫번째 인자는 토큰 내부 로직을 자세히몰라서 왜 빈칸인지는 잘 모르겠다. 중간중간에도 빈칸이 존재한다. 컴마등의 기호에도 토큰이 붙는다.
"호"라는 글자가 공백 뒤에 있을때와 다른글자 뒤에 있을때 각각 다른 ID로 지정되고 있다. 공백+글자 이렇게 묶어서 토큰이 되는것으로 알고 있다.
이번엔 영어로 해보았다.
let encoded = encoding.encode("Hello. My name is Hoyeong Lee, First name is Hoyeong and last name is Lee.");

한글과는 달리, 첫번째 인자는 빈칸이 아니긴했다. 한글이 토큰 비용면에서 불리한 느낌이 있다.
토큰수를 대략 알고 있으면, 아래 pricing 페이지에서 비용을 참고하여 계산할 수 있겠다.
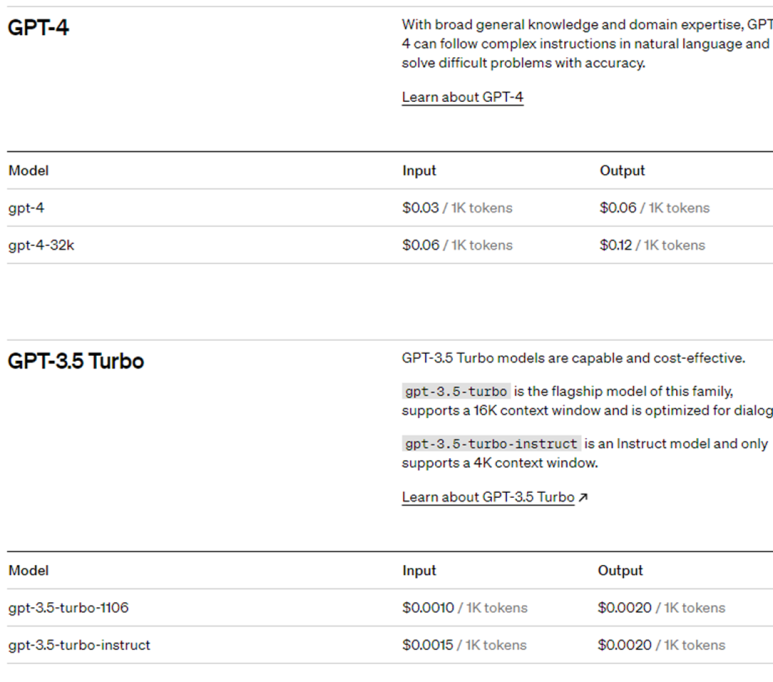
비용은 1000토큰 단위로 부과가 되는듯하고, Input(API 요청) Output (API 응답)에 따라 비용이 다르고, 보통 아웃풋이 더 비싸게 책정되어 있다.
현재 gpt3.5 모델 대비 4.0 모델은 30배 정도 비싸게 부과된다.
아주 대략적으로 10번의 일반적인 짧은 대화를 주고받고 나면 5k 토큰정도 소요되었고(상담용 챗봇 테스트 기준)
대략 0.01달러정도 쓰게되는것으로 보였다. 대략 20원 안쪽?
Pricing
Simple and flexible. Only pay for what you use.
openai.com